Jonkin aikaa sitten kirjailin nopean bash-skriptin, joka hakee haluamastaan MPD-soittolistasta tietyn verran kappaleita. Siten, että musiikkia saadaan noin tietyn aikarajan verran. Joskus kun on nimittäin kiva soittaa musiikkia sen 15 minuutin ajan, tai vaikka 45 minuuttia. Odotellessaan jotain.
Laiskana lähdin siitä, että MPD voisi hoitaa kaiken raskaan, ja bashista käsin vain kerron, mitä tehdään seuraavaksi.
- Ladataan haluttu soittolista MPD:hen.
- Sekoitellaan se. Tämä helppo tehdä MPD:n puolella.
- Pudotetaan yksi kappale listalta kunnes soittolistan kokonaispituus on alle tavoiteajan.
Ensimmäinen hahmotelma teki asioita turhan laiskasti, mutta koska kyseinen skripti on kovin henkilökohtaiseen käyttöön oleva, en nähnyt syytä ruveta tehostamaan toimintaa. Kuitenkin kun lähdesoittolistan koko alkoi kasvaa, alkoi skriptinkin suoritus hidastua kovasti. Päättelin nopeasti, että tämä on naiivi kvadraattisen suoritusajan omaava skripti:
# soittolistan pituus minuutteina
function pllength {
mpc --format "%time%" playlist |
sed -e "s/^.*) //" |
awk -F: '{s += ($1*60) ; s+=$2} END{ m=int(s/60); printf "%d\n", m;}'
}
# minuutit ovat 1. argumentti
mins="$1" ; [ -z "$1" ] && mins=15
# argumentin validius on tärkeää, ettei jouduta ikilooppiin
if [ "$mins" -le 0 ] ; then
echo "Väärä aika: $mins"
return 1
fi
# soittolista toinen vaihtoehtoinen
playlist="$2" ; [ -z "$2" ] && playlist="dinnerjazz"
echo Haetaan $mins minuuttia musiikkia...
mpc clear > /dev/null
mpc load "$playlist" > /dev/null
mpc shuffle > /dev/null
while [ `pllength` -gt "$mins" ]
do
mpc del 1 > /dev/null
done
mpc play
Soittolistaa on käsitelty epätarkasti minuuttitasolla tarkkojen sekuntien sijaan, jotta annettu aikaraja saisi vähän joustoa (15 minuutin vaatimuksen täyttäisi periaatteessa 15:30 kestävä katsaus). Nähdään melko suoraan, että määritelty apufunktio pllength vie lineaarisesti aikaa laskiessaan aina koko n-alkioisen soittolistan pituudet yhteen. Ja kun listaa aina vähennetään yhdeltä (aloittaen ylhäältä), on aika selvästi O(n²).
Nyt sitten tartuin tilaisuuteen (vaihtoehtona olisi ollut jatkaa kandin kanssa tappelua) ja kirjoitin saman mielestäni lineaarisessa ajassa. Alusta napsin pois samat argumenttitarkastukset.
echo -n Haetaan $mins minuuttia musiikkia...
mpc clear > /dev/null
mpc load "$playlist" > /dev/null
mpc shuffle > /dev/null
# funktionaalisesti voittoon: kerätään listan ajat taulukkoon.
# ( korjattu alle uusi, kts postauksen loppu)
declare -a LENGTH=(`mpc --format "%time%" playlist | awk -F: '{print $1*60}'`)
# lasketaan kertaalleen koko summa näistä.
# tehdäänpä sekin funktionaalisesti
TOTALTIME=`echo ${LENGTH[*]} | tr ' ' '+' | bc`
# nyt varsinainen bisneslogiikka taas.
i=0
(( requiredtime = mins*60 ))
while [ "$TOTALTIME" -gt "$requiredtime" ]
do
mpc del 1 > /dev/null
timerem=${LENGTH[$i]}
(( TOTALTIME = TOTALTIME - timerem ))
(( ++i ))
done
echo \ saimme $((TOTALTIME/60)) min
mpc play
Eli nyt teemme kappaleiden pituuksien ylösoton vain kerran. Ja vieläpä kovin funktionaaliseen tapaan! Laskemme kertaalleen lähtötilanteen kokonaispituuden. Tällä kertaa yksikkönä on alusta loppuun saakka sekunnit. Funktionaalisuudestaan huolimatta nämä ovat lineaarisia tuloksia, ainakin teoriassa. Käytämme dynaamisesti taulukoituja kappalepituuksia ja lyhennämme totaalista.
Tulos tuntuu nyt nopeammalta, selvästi lähempänä ideaalia O(n) -tulosta. Nyt saattaa tuo mpc shuffle olla sekin pullonkaulana, joskin minulla on muistikuva sekoittamisen olleen lineaarinen operaatio. Minuuttisysteemi tuntui olevan joustavampi, antaen välillä hieman ylimääräistä mutta ollen keskimäärin lähempänä tavoitetta kuin tämän tiukan sekuntijutun kanssa. Pitää kai vaihtaa pyöristystapaa tai lisätä löysää tuonne.
Lisäystä tai korjausta
Korjattu skripti käyttää tarkkoja mittoja kappalepituuksissa, siis sekunnilleen eksakteja. Tuloksena skripti käyttäytyy lähempänä alkuperäistä toimintaa. Ilmeisesti sekuntien trunkkaaminen ajoista tekee hyvää tasaisuudelle. Pyöristys on toisaalta aina alaspäin, mutta vastapainoksipa empiria osoittaa tulosten olevan lähempänä haluttua.
Tietysti tämä ratkaisu ei ole optimaalinen. Vastaesimerkkejä on helppo rakentaa algoritmin päälle. Jos haluamme 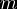
Jatkokehityksiä
Jos hifistellä haluaisi, voisi kappaleet lajitella pituuden mukaan tauluun, josta sitten painotetulla arvonnalla valittaisiin sellaisia kappaleita, jotka mahtuvat vielä olemassaolevaan tilaan. Onko tämä kysymys ollenkaan kombinatorinen, eli saako tästä edes NP-luokan ongelmaa? Emmehän voi puhua optimista (kuten vaikka “subset sum” -tapauksen tapaan), koska mielellään saisimme erilaisen tuloksen joka kerta.